插入排序同样是排序算法,它和上一篇所说的”选择排序”到底有什么区别呢?又该在什么情况下使用插入排序呢?带着疑问开始学习,在学习中尝试解答,我觉得这是一个好的学习方法。(^-^)
插入排序
插入排序,顾名思义是将元素插入到有序数组中的适当位置中。
规则
将 N 个元素的数列分为已有序和无序两个部分;
每次处理将无序数列的第一个元素与有序数列的元素从后往前逐个比较;
插入适当位置。
时间复杂度
对于随机排列的长度为 N 且值不重复的数组,最坏情况下(降序排列)需要 N^2/2 次比较和 N^2/2 次交换;最好情况(已经是升序排列)需要 N-1 次比较和 0 次交换。
平均来说,插入排序的时间复杂度为 O(n^2)。
优缺点
所需的时间取决于数组元素的初始顺序。当用插入排序排列一组有序数组或所有元素值相同的数组时,插入排序能够立即发现每个元素都已经在合适的位置上,它的运行时间是线性的。
稳定性。插入排序是在一个已经有序的小序列的基础上,一次插入一个元素。当刚开始时只有一个元素,即第一个元素。比较是从有序序列的末尾开始的,要插入的元素和有序列表的最大数开始比起,如果比它大则插入其后面,否则一直往前找到适当的位置插入。如果元素相等,那么要插入的元素会放在相等元素后面,所以相等元素的前后顺序是没有改变的。
算法实现
js代码
|
|
分析
我给insert_sort()函数增加几行 console 打印出在循环内各个参数值和数组的变化,这样可以更直观的了解到函数是如何一步步给数组排序的。

接着来看一下函数到底打印的结果:

我来一步步的解析insert_sort()函数的排序过程,当中究竟发生了什么:
我给出了数组arr=[4,2,9,5,2],共 5 个元素的数组,所以总的外循环次数也应为 5 次。对于 0 到 N-1 之间的每个 i ,将 a[i] 与 a[0] 到 a[i-1]中比它小的所有元素依次有序地交换,i 左侧的元素总是有序的。
第一轮循环 我们对照着上面的函数来看,进入for循环时,i = 0,temp = 4,j = -1;
然后到达while循环处进行判断:-1 >= 0 就已经不成立了,所以直接跳过while循环;
接下来到达if判断处:-1 != -1 也不成立,跳过if直接输出 “4—“。
这一步的作用就是把数组第一个元素插入到有序数组中,因为刚开始插入,有序数组并没有值,所以直接把无序数组第一元素插入就好,并不用判断大小。
至此,数组为:[4,2,9,5,2]
第二轮循环 此时,i = 1,temp = 2,j = 0;
到达while循环判断:0 >= 0 和 4 > 2 成立,进入while循环执行:2 = 4, j = -1,到此 j 已经不符合while循环的判断,所以不再继续循环;
然后是if判断:-1 != 0 成立,执行:4 = 2;
结束,输出 “4—“,这一步把无序数组的第一个元素 2 与 有序数组的最后一个元素 4 作比较,2 < 4 ,所以在内循环中把 4 向右移动一位,又在if中把 2 插入到有序数组的第一位置。
至此, 数组为:[2,4,9,5,2]
第三轮循环 此时,i = 2, temp = 9, j = 1;
来到while循环进行判断:1 >= 0 和 4 > 9,显然第二个表达式并不成立,所以跳过while循环;
接着是if判断:1 != 1 也不成立,跳过,直接输出 “4—“。
这一步取出无序数组的第一元素 9 ,与有序列表的最后一个元素 4 比较,4 < 9,所以直接把 9 放到 4 的后面位置即可。
至此,数组为:[2,4,9,5,2]
第四轮循环 此时,i = 3, temp = 5, j = 2;
到了while循环判断:2 >= 0 和 9 > 5 成立,执行:5 = 9,j = 1;
继续while判断:1 >= 0 和 4 > 5,第二表达式不成立,不再继续while循环;
直接到if判断:1 != 2 成立,执行:9 = 5;
这一步把无序数组第一元素 5 和有序数组 9 作比较,5 < 9 所以元素 9 向右移动一位,又判断了 5 < 4 但不成立,所以元素 5 就插入到 9 之前的位置。
至此,数组为:[2,4,5,9,2]
第五轮循环 此时,i = 4,temp = 2, j = 3;
又进行while循环判断:3 >= 0 和 9 > 2 成立,执行:2 = 9, j = 2;
继续while判断:2 >= 0 和 5 > 2 成立,执行:9 = 5, j = 1;
继续while判断:1 >= 0 和 4 > 2 成立,执行:5 = 4, j = 0;
继续while判断:0 >= 0 和 2 > 2 第二表达式不成立,跳出while循环;
接着是if判断:0 != 3 成立,执行:4 = 2;
这一步无序数组只剩下 2 ,它依次与有序数组的 9、5、4、2比较,最终插入到 4 的前面,元素 4、5、9 都依次向右移动了一位。
最终,数组为:[2,2,4,5,9]
自己把数组带入函数内,一步步的记下各个事态会让整个思路都清晰的,也能更清楚参数的变化和数组元素的移动。所以我每次都会用一个很短的数组自己手动执行一次函数,写出每时每刻的值,这样可以更好的让算法带领你一步步的移动元素、排列数组。
比较插入排序和选择排序
同样是排序算法,那么到底哪种排序算法更快呢?
选择排序无论数组是正序还是倒序排列,都要整体扫描一遍数组,而插入排序可以很快发现数字是否已在合适位置上。那么理论上插入排序应该比选择排序快,到底这个理论正不正确,我需要通过实践来验证它:
我写了两个验证函数——t1()和t2()。(验证函数源代码地址写在最后的参考文档中)这两个函数的作用都是根据传入参数 count,生成 count 组由 0 到 10 随机生成的 10 位数数组,然后计算其开始时间到结束时间的差,并分别使用插入排序和选择排序排列随即数组,看看到底哪种算法更快。
结果:
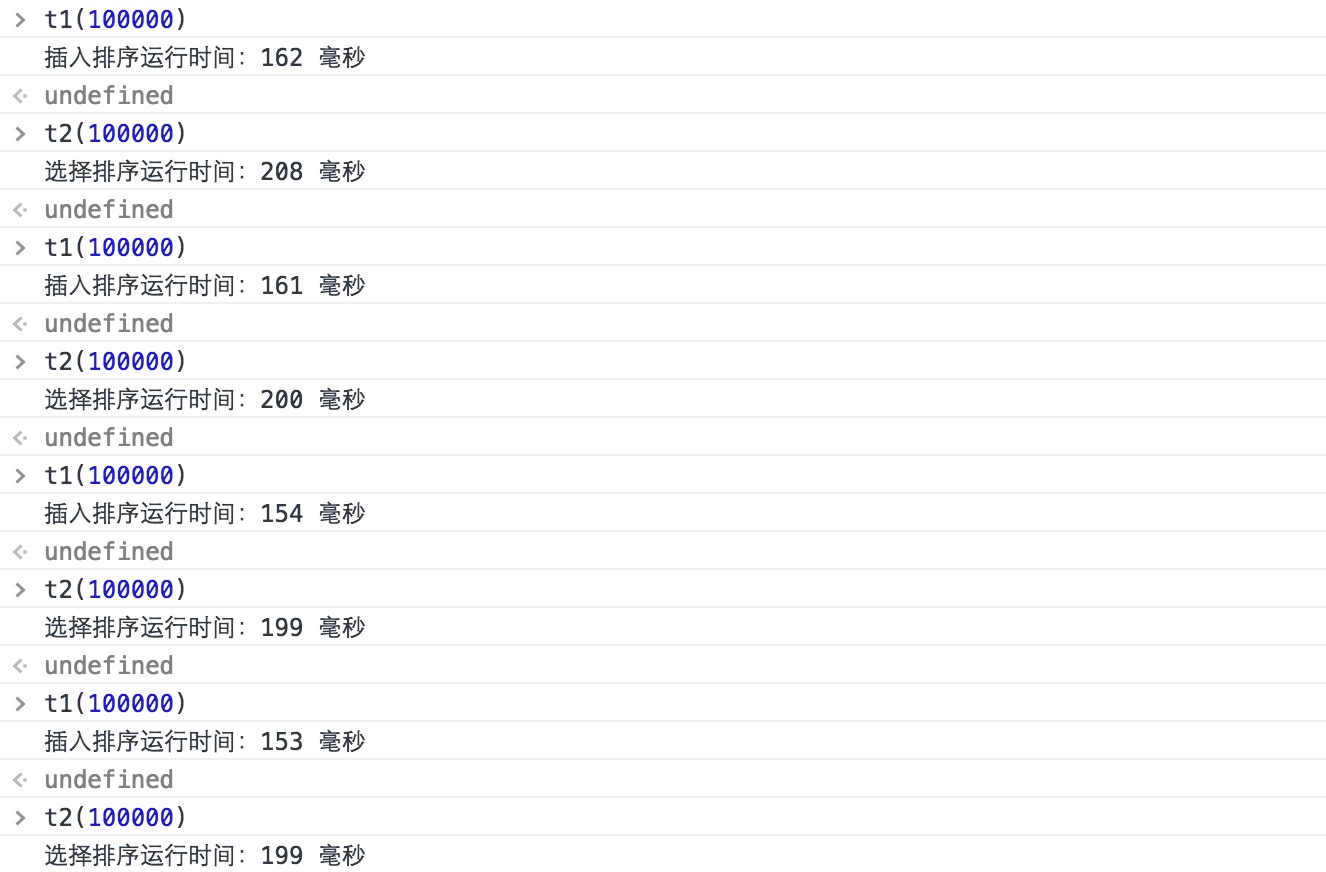
上图中,我打印出了两种排序算法的运行时间,可以看出插入排序所用时间比选择排序快一点的。虽然我传入了 100000 ,也就是生成 100000 组随机数数组,但单位是毫秒,也就是两种算法平均有0.04秒的差距,实际肉眼可见差距并不大,如果我不打印出时间来是感觉不到的。
下面我更改一下两个函数,生成由 0 到 100 随机生成的 100 位数数组,这样工作量应该大了不少,我们再来看一下两个函数的运行时间:
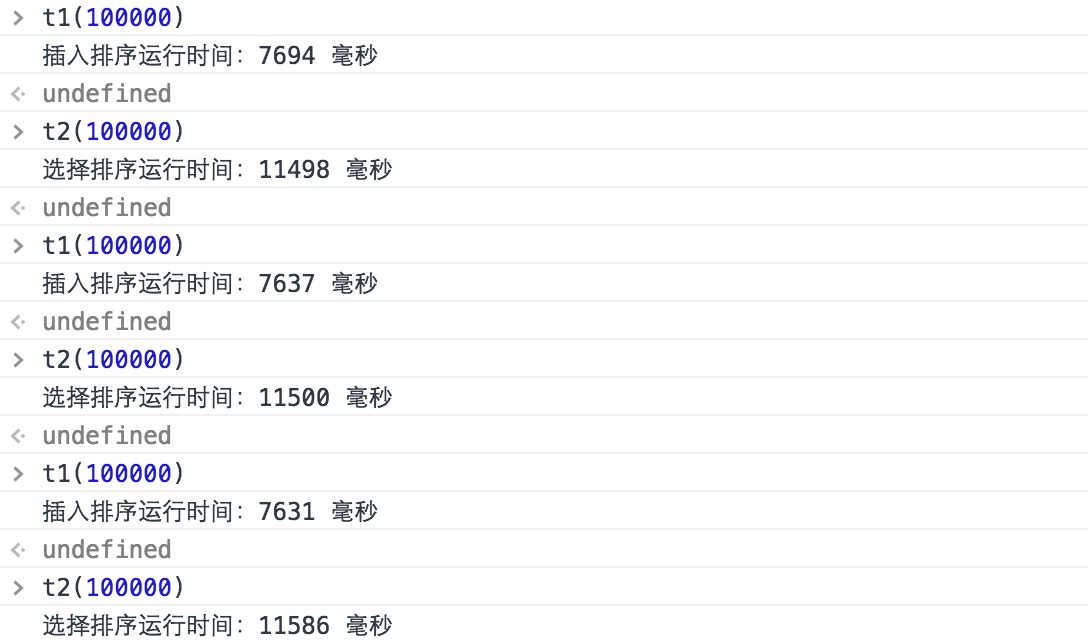
这次我只实验了三组数据,因为已经明显感觉到等待的时间了。这次选择排序的运行时间最高达到了 11586 毫秒,也就是有 11秒5 的时间在是计算中。你可以自己数 11 秒种,就能体会运行时间有多长了。
当然,这只是基于随机数组进行的实验,有兴趣的可以基于正序、倒序、元素值相同的数组进行测试。
所以,结论是 在随机数数组中,插入排序比选择排序执行速度更快 。
