希尔排序,是一种基于插入排序的快速的排序算法。希尔排序为了加快速度,交换不相邻的元素,以对数组的局部进行排序,并最终用插入排序将局部有序的数组排序。
希尔排序
希尔排序的中心思想是:使数组中任意间隔为 f 的元素都是有序的。
规则
先将要排序的一组数按某个增量 f 分成若干组,每组中记录下标相差 f;
对每组中全部元素进行排序,然后用一个较小的增量对它进行上述步骤,在每组中再进行排序;
直到增量为 1 时,即所有要排序的数分成一组。
一般的,初次取序列长度的一半为增量,以后每次减半,直到增量为 1。
时间复杂度
希尔排序的时间复杂度与增量序列的选取有关,目前已知它的运行时间达不到平方级别,在最坏的情况下希尔排序的比较次数和 N^(3/2) 成正比。平均每个增幅所带来的比较次数约为 N^(1/5),但只有在 N 很大的时候这个增幅才会变的明显。
希尔排序的时间复杂度的下界是 n*log2n。希尔排序对中等大小规模的数组表现良好,在最坏情况下和平均情况下执行效率差不多。
希尔排序是按照不同步长对元素进行插入排序,当刚开始元素很无序的时候,步长最大,所以插入排序的元素个数很少,速度很快;当元素基本有序了,步长很小,插入排序对于有序的序列效率很高。所以,希尔排序的时间复杂度会比o(n^2)好一些。
优缺点
希尔排序的执行时间依赖于增量序列。
希尔排序更高效的原因是它权衡了自数组的规模和有序性。在开始各个数组都很短,排序后数组都是部分有序的,这种情况很适合插入排序。自数组部分有序的成都取决于递增序列的选择。
代码量小且不需额外的内存空间。
如果你需要解决一个排序问题和没有系统排序函数可用,可以先用希尔排序,在考虑是否需要替换为更复杂的排序算法。
算法实现
js代码
|
|
分析
同样,我在上面的代码中加入几行 consloe 打印出在循环中各个参数的值和数组状态:

我在函数中声明了一组有 5 个元素的数组,接下来看下图的打印结果,可以更好的理解希尔排序的交换过程:
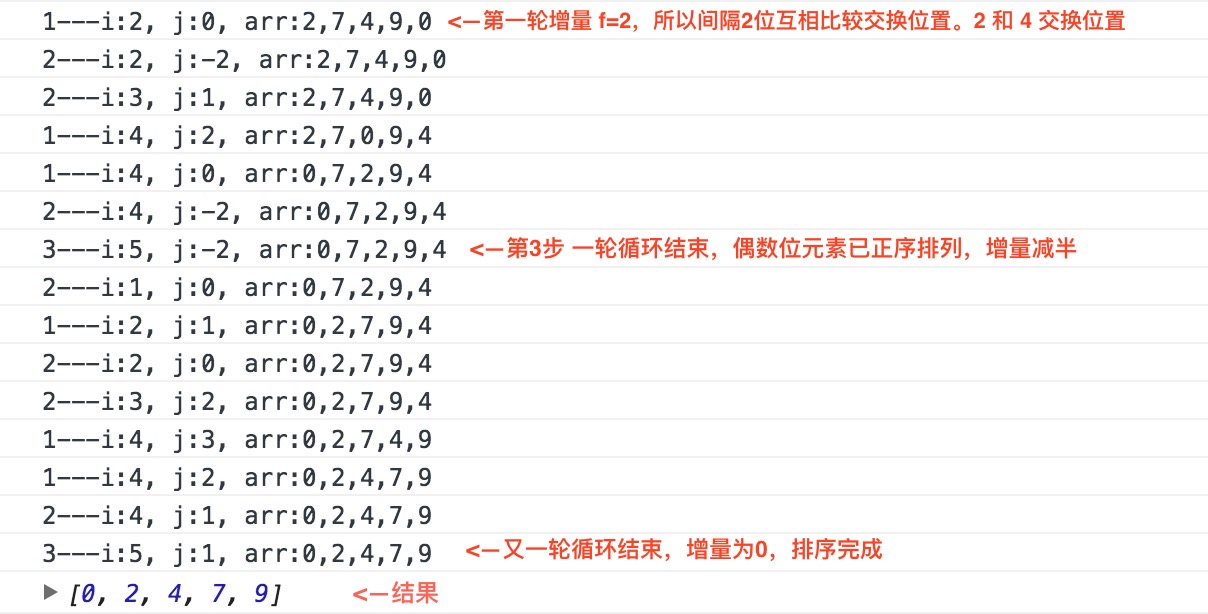
想弄懂希尔排序到底是怎么一步步交换元素的,我自己手动把数组带入执行了一遍函数。中间失败了好几次,- -因为循环嵌套是在太多了,导致我转着转着就蒙圈了。我觉得这个办法虽然笨,但是对于理解一个函数的运作是最直接不过的了。
整体的交换过程为:2 -> 4 [2,7,4,9,0]0 -> 4 [2,7,0,9,4]0 -> 2 [0,7,2,9,4]
第一轮结束,增量为17 -> 2 [0,2,7,9,4]9 -> 4 [0,2,7,4,9]7 -> 4 [0,2,4,7,9]
第二轮结束,增量为0
这里我就不把带入过程写下来了,说一下希尔排序的大致思路吧:
首先,从上面所写的交换过程很容易找出规律,结合希尔排序的规则来看,此时的增量为 Math.floor(5/2)(向下取整5/2 = 2),所以我们可以看作是从数组 0 下标开始隔一个取一个,也就是[4,2,0]。
然后,把这三个元素按照大小互相交换位置,排序并不影响另外两个元素的位置,只在这三个元素的位置上互相交换,结果为[0,7,2,9,4]。
最后,开始下一轮循环,此时增量为 Math.floor(2/2)(向下取整2/2 = 1)。这时增量为1,也就是数组元素挨个比较并排序,就跟用插入排序的排序规则是一样的了。
也就是说,希尔排序会先把相隔增量的元素用插入排序的规则排好位置,然后再把相隔增量/2的元素用插入排序排好位置,这样直到增量为1,就把元素挨个用插入排序检查大小并排序。
现在你应该可以理解,为什么希尔排序可以把位于数组末尾的最小值很快的移动到数组前面了,因为它比插入排序的检查和移动间隔大,当然执行速度也就越快。相当于我们传给插入排序一个相对有序的数组,当然运行更快了。
比较希尔排序和插入排序
为了证实青出于蓝而胜于蓝的希尔排序,跟以前一样,我测试了一下两种算法的运行时间。分别对两种算法生成100位随机数数组,然后进行排序,看运行时间。(测试运行时间的代码可以到我的Github上找,地址我会写在参考文档中)
结果:
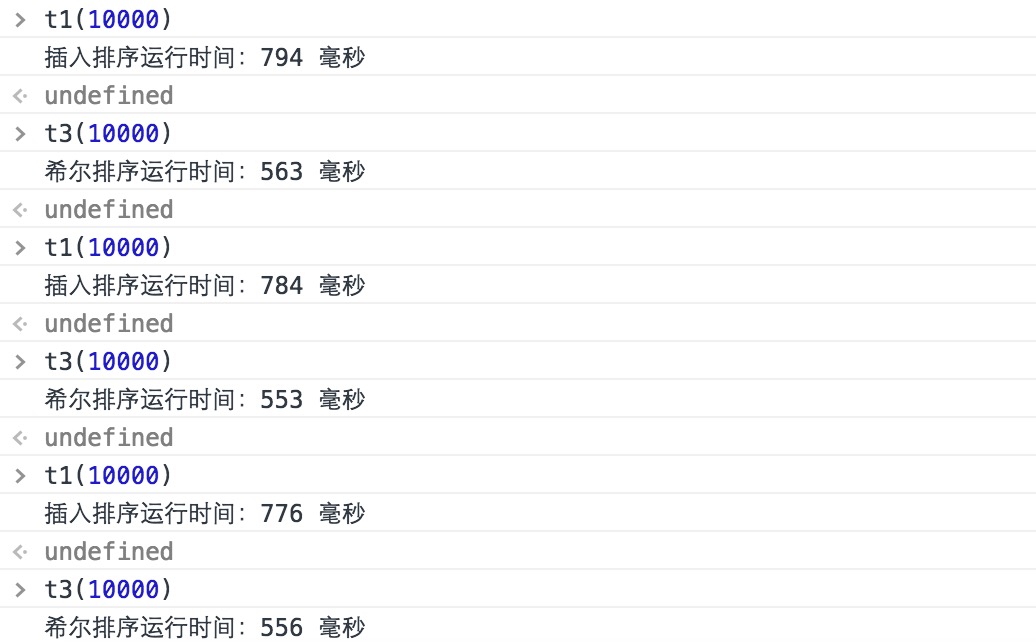
看上图,我生成了 10000 组随机数组,可以看出,希尔排序的运行时间是比插入排序快的。这个测试只针对随机数组,有兴趣的可以尝试传入正序或倒序数组再进行测试,看看结果是否一样。
