堆排序是集归并排序和插入排序有点的一种排序算法,它与插入排序一样具有空间原址性,并且与归并排序一样,堆排序的时间复杂度是 O(nlgn)。
堆排序
堆排序使用了一种称为”堆”的数据结构来进行排序。所以想学习堆排序,先要了解”堆”的概念。堆不仅仅应用在堆排序中,它还可以构造一种有效的优先队列。
堆
堆,一个可以被看作一棵近似的完全二叉树的数组对象。树上的每个结点对应数组中的一个元素,元素从左向右填充。根结点为数组最大值时称为最大堆,根结点为最小值时称为最小堆。而不论是最大堆或最小堆,结点值都要满足堆的性质,也就是某个结点值总是不大于或不小于其父结点的值。
树的根结点是数组下标 0 的元素,也就是 A[0] ,如果我给定一个结点下标 i,很容易的可以计算得出它的父结点和左右子结点的下标。也就是:
Parent = i/2 (结果向下取整)
Left = 2i + 1
Right = 2i + 2
规则
从无序的输入数组中构造一个最大堆;
对数组进行原址排序,维护最大堆的性质,最大值元素在根结点中;
已经构建好的最大堆,通过互换 A[0] 与 A[n] 的位置,从堆中去掉最大元素,使其在正确的位置;
此时重新维护最大堆的性质,并重复交换步骤,直到数组从小到大排列好。
时间复杂度
包含 n 个元素的堆的高度是 lgn,堆结构上的一些基本操作的运行时间至多与树的高度成正比,即时间复杂度为 O(lgn)。
优缺点
构建初始堆所需要的比较次数多,所以不适宜数据较少的排序
堆排序是原地排序,辅助空间为 O(1)
堆排序是不稳定的排序,也就是相同元素排序后的前后顺序会改变
算法实现
js代码
|
|
分析
我来分析一下堆排序的操作过程,看图:
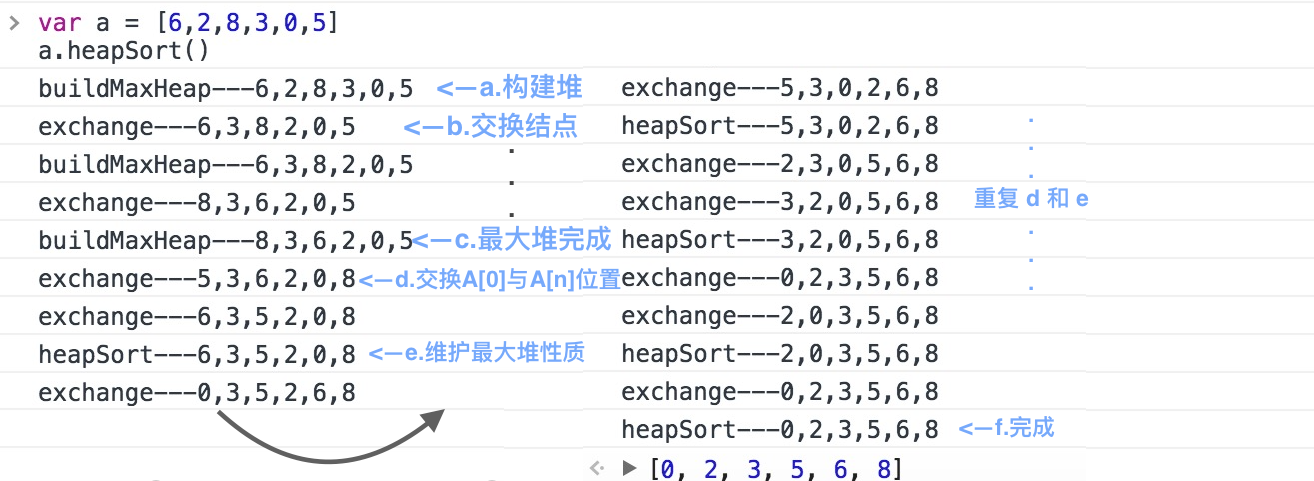
堆排序首先要对数组构建初始”堆”,形态为 a 。接着从底层开始向上,维护最大堆的性质,如 b ,父结点 2 小于左子结点 3,所以交换两个结点位置。重复此步骤直至堆结构符合最大堆性质,形如 c。
此时数组状态为:[8, 3, 6, 2, 0, 5]
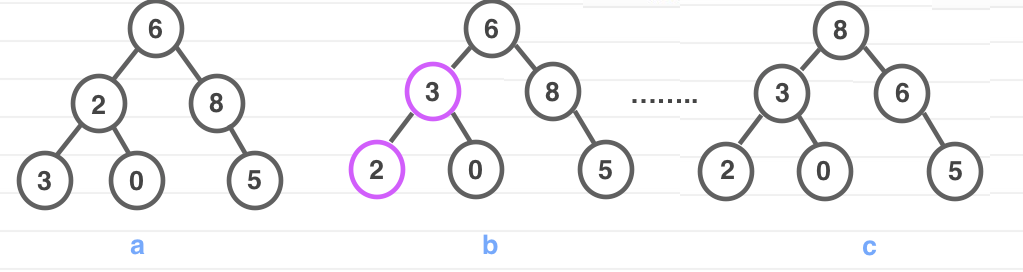
然后开始进行堆排序,堆的根结点也就是数组中的最大元素,为了符合排序后的大小顺序,我们每次都把根结点与数组末尾元素进行互换,并重新进行维护最大堆性质。
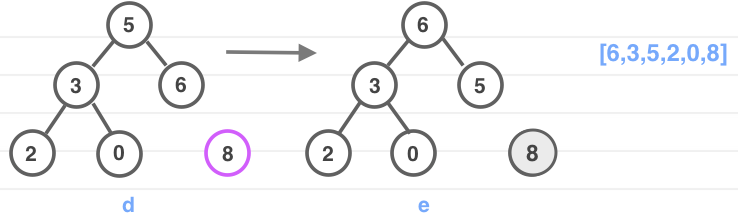
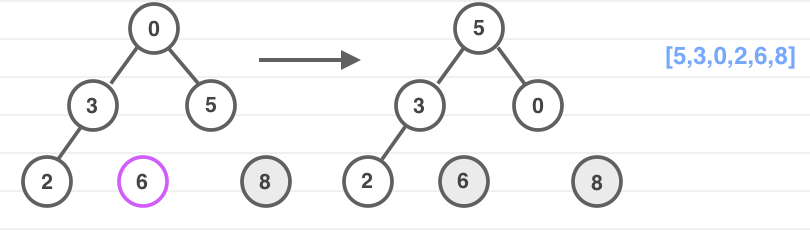
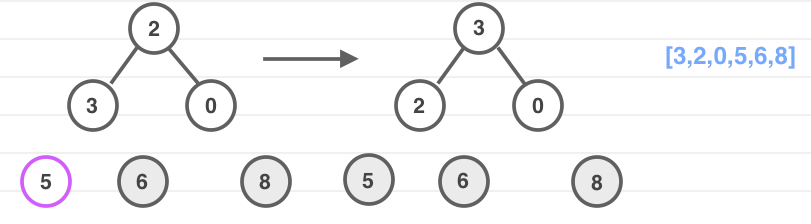
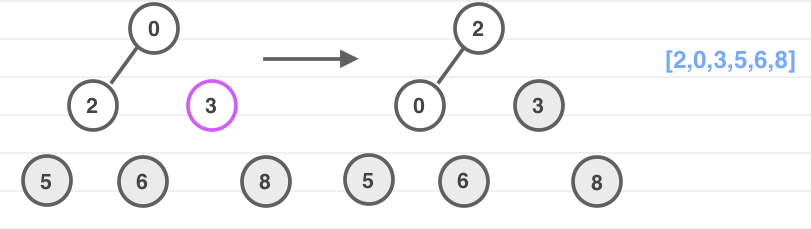
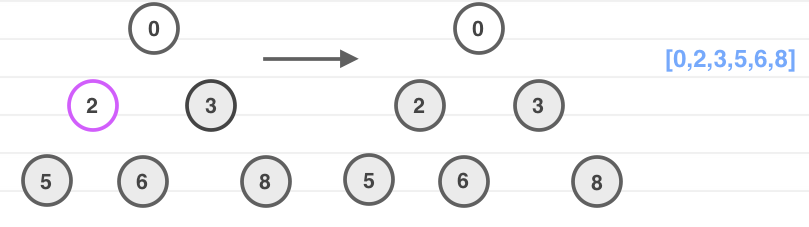
无非是把最大堆转换成最小堆的过程。
